
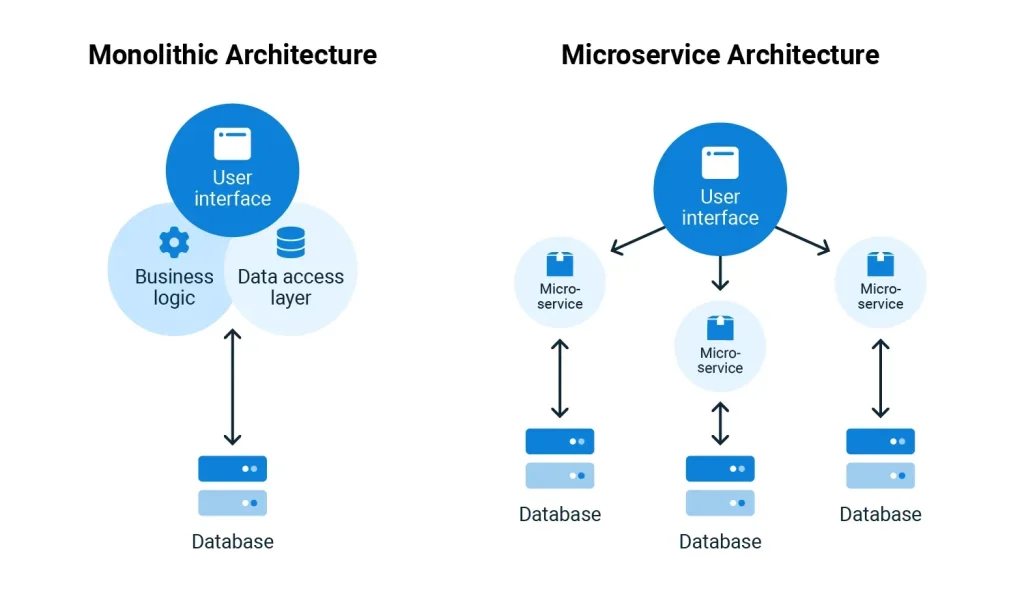
Monolith to Microservices signals a pivotal shift in how organizations scale software, aiming to balance stability with rapid, continuous delivery. As teams grow and product lines expand, a tightly coupled monolith can become a bottleneck that slows releases, hinders experimentation, and complicates scaling. A thoughtful approach emphasizes decomposing a monolith into bounded contexts that evolve independently, enabling teams to own their services while maintaining overall system coherence. A disciplined, incremental approach guides the move with pilots, governance, and robust rollback mechanisms to safeguard continuity. This practical, business-oriented roadmap highlights architecture choices, data considerations, and governance essentials to help organizations realize modularity and resilience.
Beyond the specific terminology, the journey resembles a transition to a distributed, service-based architecture where a single monolith is partitioned into focused, independently deployable components. Practically, organizations pursue a modularization path that emphasizes bounded contexts, API contracts, and event-driven patterns to support autonomous teams and safer deployments. The approach aligns with a modern service-oriented transformation, prioritizing data ownership, governance, and observability as core capabilities. By focusing on business capabilities rather than code structure, firms can evolve with minimal disruption while gradually expanding their resilient service ecosystem.
Monolith to Microservices: A Practical Migration Plan for Incremental Delivery
Transitioning from a monolith to microservices begins with a structured microservices migration plan that minimizes risk and preserves business continuity. Framing the effort as a monolith migration strategy rather than a rip-and-replace approach helps teams decompose a monolith into bounded contexts, validate service boundaries, and deliver value in short iterations. Start with a small pilot service with clear responsibilities and data ownership to establish a repeatable pattern for subsequent extractions.
Design the target microservices architecture with modularity and autonomy in mind. Define service interfaces, decide between shared databases and database-per-service models, and implement resilience through API gateways and service meshes. This decomposing a monolith activity informs the broader microservices migration plan and provides a practical blueprint for expanding the ecosystem while maintaining business continuity.
Designing a Resilient Microservices Architecture: Boundaries, Data Ownership, and Observability
To build a robust microservices architecture, teams must establish clear boundaries and data ownership. Applying bounded contexts ensures each service owns its domain data and logic, reducing cross-service coupling. Supporting patterns like API gateways and service meshes provide a controlled, observable communication layer, while a thoughtful data strategy—whether data remains centralized or per-service—keeps data consistent across boundaries and supports independent deployment.
Governance, security, and observability must be integral to the migration. Implement automated security tests in CI/CD, enforce unified identity management, and instrument end-to-end tracing and metrics to monitor health and performance. With these controls in place, organizations can accelerate the monolith to microservices journey while maintaining compliance, risk management, and predictable delivery as outlined in a comprehensive microservices migration plan.
Frequently Asked Questions
What is a practical monolith to microservices migration strategy for moving from a monolith to microservices?
Adopt an incremental monolith migration plan rather than a big-bang rewrite. Start with a small, well-scoped pilot that decomposes the monolith into bounded contexts aligned with business capabilities. Use domain-driven design to define service boundaries, data ownership, and interaction patterns. Choose a vertical slice approach to minimize cross-service dependencies, automate deployment and testing, and apply governance to maintain continuity while delivering measurable value as you move toward a true microservices architecture.
How should data be managed when decomposing a monolith in a microservices architecture as part of a monolith to microservices effort?
Plan data ownership and migration early. Decide which data stays in the monolith and which moves to services, and pick a data strategy—shared database, database per service, or event-driven replication. Use patterns such as outbox and dual-write to keep data consistent during the transition. Align each data domain with its owning microservice to enable independent evolution and maintain eventual consistency where appropriate.
| Key Point | Description | Notes/Section |
|---|---|---|
| Stability vs Speed | The software industry balances reliability with rapid releases; as organizations grow, a monolith can slow releases, complicate scaling, and increase risk. | Introduction / Rationale |
| Four Core Pillars | Architecture design, migration strategy, data management, and operations & governance are the central axes for moving from a monolith to microservices. | Foundation for the roadmap |
| Benefits and Cautions | Monolith to Microservices can enable faster releases, better fault isolation, technological diversity where appropriate, and team scaling by business capability; however, a poorly planned migration adds risk. | Why consider the shift / Risk awareness |
| Practical Roadmap Approach | The roadmap is adaptable across domains, emphasizing incremental delivery, governance, and measurable outcomes. | Roadmap Philosophy |
| Step 1: Assess & Define Boundaries | Map modules, data stores, and dependencies; identify bounded contexts; use domain-driven design to outline candidate microservices; start with a small pilot service with clear boundaries; inventory cross-cutting concerns (authentication, logging, etc.). | Step 1 Details |
| Step 2: Design Target Architecture | Emphasize modularity and clear contracts; define interfaces and data boundaries; choose REST/gRPC for direct calls and asynchronous messaging for decoupled workflows; establish an organizational model aligning teams with services. | Key Architectural Choices |
| Step 3: Migration Plan | Plan is incremental and bounded by business value; start with vertical slices of standalone capabilities; define success criteria and address data migration patterns (dual-write, outbox, event-driven replication). | Migration Strategy |
| Step 4: Implement First Wave | Build autonomous deployment pipelines, automated tests, robust rollback, and governance that avoids drift; use containers (Docker) and orchestration (Kubernetes); CI/CD with security checks and canary deployments; embed observability from day one. | Implementation Details |
| Step 5: Validate & Expand | Measure deployment frequency, lead time, SLOs, error rates, and latency; refine boundaries and data ownership; iterative expansion of services as confidence grows. | Measurement & Iteration |
| Step 6: Governance & Security | Establish clear ownership, enforce security policies, automate security tests in CI/CD, and conduct risk assessments and threat modeling; unify identity management, auditing, and data protection while preserving service autonomy. | Governance & Compliance |
| Step 7: Pitfalls & Best Practices | Common pitfalls include over-coupling, premature optimization, and neglecting data governance; best practices emphasize pilot scope, bounded contexts, eventual consistency, strong observability, automated CI/CD, and aligning teams with services. | Common Guidance |
Summary
A table outlining the key points from the base content and a concluding SEO-friendly summary follow.

